목 차
robots.txt 이란?
웹소유자가 스파이더에게 자신의 사이트를 어떻게 크롤링할지 제어할 수 있게 해 주는 텍스트 파일입니다.
스파이더란, 웹사이트를 탐색하고 내용을 수집하는 프로그램을 의미하며, 웹크롤러(web crawler), 봇(bot), 로봇(robot)이라고도 불립니다.
robots.txt 파일은 주로 웹사이트의 특정 부분에 대한 스파이더 접근을 허용하거나 차단하는 역할을 합니다. 예를 들어, 개인정보가 포함된 페이지가 검색 결과로 나타나지 않도록 제어하는 것입니다.
또한 robots.txt 파일은 웹검색 스파이더의 내용 수집을 제어하기 때문에, 잘못 내용을 구성하면 검색 엔진의 탐색과 색인을 차단하기 때문에 검색엔진 노출이 안 될 수도 있습니다.
따라서 robots.txt를 다룰 땐 제대로 이해하여 정확한 문구로 작성하는 게 중요합니다.
robots.txt 설정과 보는 법, 구문 및 명령어 이해하기
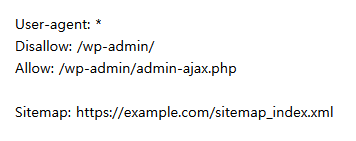
robots.txt 파일의 구문을 이해하는 것은 앞에서 말했듯, 검색 엔진 최적화에 매우 중요합니다. 이 파일은 주로 사용자 에이전트(user-agent), 금지(disallow), 허용(allow), 사이트맵(sitemap), 크롤 지연(crawl-delay)과 같은 명령어로 구성됩니다.
그럼, 각각 예시를 들면서 쉽게 설명 드리겠습니다.
사용자 에이전트(User-Agent): 이 부분은 특정 검색 엔진 스파이더나 크롤러를 지정합니다. 예를 들어, User-agent: Googlebot이라고 작성하면 이 구문은 Google의 크롤러에만 적용됩니다. 모든 크롤러에게 적용하고 싶다면 User-agent: *로 설정할 수 있습니다.
금지(Disallow): 이 명령어는 특정 URL이나 웹사이트의 섹션을 검색 엔진 크롤러가 접근하지 못하도록 차단합니다. 예를 들어, Disallow: /private는 ‘/private’ 경로의 모든 페이지를 크롤링으로부터 차단합니다.
허용(Allow): 특정 페이지나 섹션을 크롤러가 접근할 수 있도록 허용합니다. 이것은 Disallow 명령어와 함께 사용되어 특정 규칙의 예외를 만듭니다.
예를 들어, Disallow: /folder와 Allow: /folder/page.html을 함께 사용하여 ‘folder’ 내의 모든 페이지를 차단하지만 ‘page.html’만 허용할 수 있습니다.
사이트맵(Sitemap): 이 명령어는 검색 엔진 크롤러에게 사이트맵의 위치를 알려줍니다. 이를 통해 크롤러는 사이트의 구조를 더 잘 이해하고 효율적으로 크롤링할 수 있습니다.
예: Sitemap: https://www.example.com/sitemap.xml
크롤 지연(Crawl-Delay): 이 명령어는 크롤러의 사이트 방문 간격을 설정할 수 있게 해주는 것으로, 웹사이트 서버에 과부하가 가지 않도록 합니다. 이 명령어는 모든 검색 엔진에 적용되지는 않지만, 일부 검색 엔진에서는 크롤링 간격을 조정하는 데 유용합니다.
예를 들어, Crawl-delay: 10은 크롤러가 사이트를 재방문하기 전에 10초를 기다리라는 지시입니다.
robots.txt에서 와일드카드 활용하기
robots.txt 파일에서 와일드카드(wildcard) 문자를 사용하는 것은 검색 엔진 크롤러에 대한 지시를 보다 유연하게 설정할 수 있게 해줍니다. 와일드카드 문자에는 주로 * (별표)와 $ (달러 기호)가 사용됩니다.
* (별표) 와일드카드: 이 와일드카드는 “모든 것” 또는 “어떤 문자열도”를 의미합니다.
예를 들어, User-agent: 는 모든 유형의 크롤러에 대한 지시사항이 적용됨을 의미합니다. 또 다른 예로, Disallow: /tmp/는 ‘/tmp/’ 경로 하위의 모든 파일과 폴더에 대한 접근을 차단하라는 지시입니다.
$ (달러 기호) 와일드카드: 이 와일드카드는 URL의 끝을 나타내는 데 사용됩니다.
예를 들어, Disallow: /*.pdf$는 확장자가 ‘.pdf’로 끝나는 모든 파일을 차단하라는 명령입니다. 이 경우, ‘.pdf’로 끝나는 모든 URL이 크롤러에 의해 무시됩니다.
이러한 와일드카드 문자를 사용하면, robots.txt 파일에서 보다 세밀하게 크롤링 규칙을 설정할 수 있으며, 특정 유형의 파일이나 경로에 대한 접근을 쉽게 제어할 수 있습니다. 와일드카드를 활용함으로써, 웹사이트 관리자는 검색 엔진 크롤러가 사이트를 탐색하는 방식을 더 효과적으로 관리할 수 있습니다.
검색 엔진 크롤러(탐색 및 수집) 관리하기
robots.txt 파일에서 검색 엔진 크롤러를 관리하는 방법은 간단합니다. 여기서는 Googlebot, Bingbot, DuckDuckBot 같은 특정 크롤러에 대한 지시사항을 어떻게 맞춤 설정하는지 살펴보겠습니다.
특정 크롤러 지정하기: robots.txt 파일에서는 User-agent 명령어를 사용하여 특정 검색 엔진 크롤러를 지정할 수 있습니다.
예를 들어, User-agent: Googlebot이라고 쓰면, 이후의 지시사항들은 Googlebot에만 적용됩니다. 마찬가지로, User-agent: Bingbot라고 쓰면 Bingbot에게만 해당하는 지시사항들이 적용됩니다.
크롤 지연 설정하기: 특정 크롤러에 대해 사이트 방문 간격을 조정할 수도 있습니다. 이를 Crawl-delay 명령어로 설정합니다.
예를 들어, User-agent: DuckDuckBot 다음에 Crawl-delay: 10이라고 적으면, DuckDuckBot은 사이트에 대한 재방문 시 10초 간격을 두고 크롤링을 해야 합니다. 이는 서버에 부담을 줄이는 데 도움이 됩니다.
이러한 방법으로 robots.txt를 사용하면, 웹사이트 소유자는 다양한 검색 엔진 크롤러가 자신의 사이트를 어떻게 크롤링할지를 제어할 수 있습니다. 이는 웹사이트의 서버 부하를 관리하고, 특정 검색 엔진에 대해 사이트의 콘텐츠 노출을 최적화하는 데 중요한 역할을 합니다. 서버의 성능이 충분하다면, 굳이 검색 엔진의 지연을 설정할 필요는 없다고 생각합니다. 검색 엔진도 수집이 잘 되는 사이트를 더 선호하기 때문입니다.
흔히 하는 실수와 이를 피하는 방법
robots.txt 파일을 작성할 때 발생할 수 있는 몇 가지 흔한 실수와 이를 방지하는 방법들에 대해 살펴보겠습니다.
설정 오류: 가장 흔한 실수 중 하나는 잘못된 구문이나 오타입니다.
예를 들어, Disallow: /folder 대신에 Dissallow: /folder와 같이 잘못 입력하는 경우가 있습니다. 이런 실수는 크롤러가 웹사이트를 의도하지 않은 방식으로 크롤링하게 만들 수 있습니다.
색인 제거 위험: Disallow 명령어를 사용할 때는 주의가 필요합니다. 잘못된 경로를 지정하면, 검색 엔진이 웹사이트의 중요한 페이지를 크롤링하지 않을 수 있습니다.
예를 들어, Disallow: /는 웹사이트 전체를 크롤링에서 제외시키므로, 이는 대부분의 경우 원치 않는 결과를 초래합니다.
테스트 도구 사용: robots.txt 파일을 작성한 후에는 반드시 검증해야 합니다. 구글 검색 콘솔(Google Search Console) 같은 테스트 도구를 사용하여 robots.txt 파일이 올바르게 작동하는지 확인할 수 있습니다. 이 도구를 사용하면 구문 오류나 잘못된 명령어가 있는지 검사할 수 있으며, 이를 통해 실수를 미리 발견하고 수정할 수 있습니다.
구글 서치 콘솔 robots.txt 보고서 :
https://support.google.com/webmasters/answer/6062598?hl=ko
이러한 방법으로 robots.txt 파일에서 발생할 수 있는 실수를 최소화하고, 웹사이트가 검색 엔진에 의해 효과적으로 크롤링되고 색인되도록 할 수 있습니다. 정확한 robots.txt 설정은 웹사이트의 검색 엔진 최적화(SEO) 성과에 중요한 역할을 하므로, 주의 깊게 관리하는 것이 중요합니다.
robots.txt 만드는 방법 및 업로드 하기
robots.txt 파일을 만들고 업로드하는 방법은 간단합니다. 다음 단계를 따라하면 쉽게 할 수 있습니다.
- robots.txt 파일 만들기:
먼저, 텍스트 편집기(예: 메모장, Notepad++, Sublime Text)를 엽니다.
robots.txt 파일에 필요한 명령어를 입력합니다. 예를 들어, User-agent: *와 Disallow: /private-folder/ 같은 명령어를 사용하여 모든 크롤러가 특정 폴더에 접근하는 것을 차단할 수 있습니다.
파일을 robots.txt라는 이름으로 저장합니다. 파일 이름과 확장자가 정확히 맞는지 확인하세요.
- robots.txt 파일 업로드하기:
파일을 웹사이트의 루트 디렉토리에 업로드해야 합니다. 대부분의 경우, 웹사이트 호스팅 제어판을 통해 파일을 업로드할 수 있습니다.
FTP 클라이언트(예: FileZilla)를 사용하여 파일을 서버에 직접 업로드할 수도 있습니다. 이 경우, FTP 계정 정보가 필요합니다.
파일을 업로드한 후에는 웹 브라우저를 통해 https://www.도메인.com/robots.txt로 접속하여 파일이 제대로 업로드되었는지 확인합니다. 다른 사이트들의 robots.txt는 어떻게 구성했는지도 위와 같은 https://www.도메인.com/robots.txt 과 같은 방법으로 벤치마킹도 가능합니다.
참고로 구글 robots: https://www.google.com/robots.txt
- 테스트 및 검증:
업로드한 robots.txt 파일이 제대로 작동하는지 확인하기 위해 Google Search Console과 같은 도구를 사용하여 테스트합니다. 파일에 문제가 없는지 확인한 후, 실제로 검색 엔진이 파일을 인식하고 있는지 확인해야 합니다.
이렇게 단계별로 진행하면, robots.txt 파일을 쉽게 만들고 웹사이트에 적용할 수 있습니다. 이 파일은 웹사이트의 SEO에 중요한 역할을 하므로, 신중하게 작성하고 업로드하는 것이 중요합니다.
감사합니다.
행복하세요!